
최근 프로젝트에서(https://bangbaeking.tistory.com/160) Kafka를 사용했지만, 면접에서 "Kafka 클러스터가 뭔가요?" 라는 질문에 정확히 답변하지 못했다. (브로커를 여러개 설정해서 어쩌구 고가용성 저쩌구) 그래서 카프카 클러스터가 뭔지 정리해보려고 한다. 결론부터 정리하면 Kafka 클러스터는 여러 개의 브로커로 구성된 분산 시스템으로, 데이터의 고가용성과 확장성을 보장하는 Kafka의 핵심 구조이다.
카프카란?
Apache Kafka는 대용량 데이터의 실시간 스트리밍을 처리하기 위한 분산 메시지 큐 시스템이다.
대규모 데이터 파이프라인, 실시간 데이터 분석, 로그 수집, 이벤트 기반 아키텍처 등에 활용된다.
Kafka의 주요 특징은 다음과 같다.
- 높은 처리량(High Throughput): 초당 수백만 개의 메시지를 처리 가능
- 분산 아키텍처(Distributed Architecture): 여러 노드로 구성되어 확장성이 뛰어남
- 내결함성(Fault Tolerance): 데이터 복제를 통해 장애 발생 시에도 안정적인 운영 가능
- 확장성(Scalability): 노드를 추가하여 성능을 손쉽게 확장 가능

카프카 클러스터
Kafka는 여러 개의 브로커(Broker)로 구성된 클러스터(Cluster) 형태로 동작한다.
Kafka 클러스터의 주요 특징은 다음과 같다.
- 데이터 분산 저장: 메시지가 여러 브로커에 나뉘어 저장됨
- 고가용성(High Availability): 데이터 복제를 통해 장애 발생 시 데이터 손실 최소화
- 확장성(Scalability): 브로커를 추가하여 성능을 향상 가능
브로커(Broker)
Kafka 클러스터를 구성하는 개별 서버(노드)로, 메시지를 저장하고 관리하는 역할을 한다.
각 브로커는 특정 파티션의 리더 또는 팔로워 역할을 맡을 수 있다. (파티션에 대한 내용은 아래에서 추가 설명)
브로커의 주요 특징
- 데이터 저장: 프로듀서(Producer)로부터 데이터를 받아 저장
- 데이터 제공: 컨슈머(Consumer)에게 저장된 데이터를 전달
- 토픽 관리: 특정 토픽의 파티션을 관리하며 리더와 팔로워 역할 수행
토픽(Topic)
Kafka에서 메시지를 분류하는 단위이다.
토픽의 주요 특징
- 프로듀서(Producer)는 특정 토픽으로 메시지를 전송
- 컨슈머(Consumer)는 원하는 토픽을 구독하여 메시지를 소비
- 하나의 토픽은 내부적으로 여러 개의 파티션(Partition)으로 구성
파티션(Partition)
토픽을 나누는 단위로, Kafka의 데이터 분산과 병렬 처리를 가능하게 하는 핵심 요소이다.
파티션의 주요 특징
- 하나의 토픽은 여러 개의 파티션으로 구성될 수 있으며, 각 파티션은 서로 다른 브로커에 분산 저장됨
- 각 파티션에는 고유한 번호가 부여되며, 메시지는 append-only 형태로 저장됨
- 파티션에는 리더(Leader)와 팔로워(Follower)가 존재
- 리더: 읽기 및 쓰기 작업을 처리
- 팔로워: 리더의 데이터를 복제하며, 리더 장애 시 자동 승격됨
- 파티션 개수를 늘리면 병렬 처리 성능이 향상되지만, 컨트롤러 및 브로커의 오버헤드 증가, 컨슈머 그룹 리밸런싱 비용 상승, 네트워크 부하 증가 등의 단점이 발생할 수 있음
세그먼트(Segment)
Kafka의 파티션 내에서 메시지를 저장하는 물리적 파일 단위이다.
프로듀서(Producer)가 Kafka에 메시지를 전송하면, 메시지는 어떤 토픽(Topic)과 파티션(Partition)에 저장될지 결정된다.
- 메시지에 키(Key)가 있는 경우: 특정 파티션에 매핑됨 (해시 기반)
- 키(Key)가 없는 경우: 라운드 로빈(round-robin) 방식으로 파티션이 할당됨
브로커(Broker)는 해당 메시지를 할당된 파티션(Partition)의 리더(Leader)에게 저장한다
파티션(Partition) 내부에서 메시지는 세그먼트(Segment) 형태로 저장됨
- 각 파티션은 하나 이상의 세그먼트 파일로 구성됨
- 메시지는 가장 최신 세그먼트(Active Segment)에 추가(append-only)됨
- 세그먼트가 설정된 크기(log.segment.bytes) 또는 시간(log.segment.ms)을 초과하면 새로운 세그먼트가 생성
Kafka 클러스터에서는 각 브로커가 리더 파티션과 팔로워 파티션을 관리하는데, 그렇다면 리더 선출은 어떻게 이루어질까?
컨트롤러(Controller)
Kafka 클러스터에는 컨트롤러 역할을 담당하는 브로커가 하나 존재하며, 클러스터 전체를 관리한다.
컨트롤러의 주요 역할
- Kafka 클러스터의 브로커와 파티션 관리
- 리더 선출(Leader Election) 수행
- 브로커 추가/제거 감지 및 장애 감지
컨트롤러는 클러스터 내 하나의 브로커가 담당하며, 장애 발생 시 새로운 컨트롤러가 자동으로 선출됨.
컨트롤러(Controller) 선출 방식
Kafka 2.8 이전 (Zookeeper 사용)
- Kafka가 실행될 때, 주키퍼(Zookeeper)가 Kafka 브로커 중 하나를 컨트롤러로 선출
- 컨트롤러 장애 발생 시 주키퍼가 새로운 컨트롤러를 선출
Kafka 2.8 이후 (KRaft 사용, Zooleeper 제거)
- Kafka 자체적으로 Raft 기반 합의(Consensus) 알고리즘을 사용하여 컨트롤러를 선출
- Kafka 브로커 중 하나가 자동으로 컨트롤러가 됨
- 컨트롤러 브로커 장애 발생 시, KRaft가 새로운 컨트롤러를 선출
Kafka 2.8 이후 KRaft 모드의 장점
- 주키퍼 없이 Kafka만으로 클러스터 운영 가능
- 컨트롤러 및 리더 선출 속도 향상 → 장애 복구 속도 향상
- 메타데이터 관리 최적화 → 클러스터 성능 개선
- Kafka 운영 복잡도 감소 → 운영 부담 감소
즉, Kafka 2.8 이후부터는 주키퍼 없이 Kafka 자체적으로 컨트롤러 선출, 브로커 관리, 리더 선출 등이 가능해졌다.
주키퍼(Zookeeper)란?
Apache Zookeeper는 분산 시스템을 위한 중앙 집중식 코디네이션 서비스로, Kafka에서는 클러스터 관리 및 메타데이터 저장 용도로 사용되었다.
즉, Kafka 브로커 간의 클러스터 상태 관리, 리더 선출(Leader Election), 브로커 등록 등의 핵심 역할을 수행하는 필수 컴포넌트였다.
그러나 Kafka 2.8 이후 KRaft(Kafka Raft) 방식이 도입되면서 Zookeeper 없이도 Kafka 운영이 가능해졌다. 다만, 기존 Zookeeper 기반 방식과 KRaft 기반 방식이 공존하는 형태이며, 완전히 제거된 것은 아니다.
코디네이터(Coordinator)
Kafka 클러스터에서는 각 컨슈머 그룹을 관리하는 코디네이터 역할을 담당하는 브로커가 존재하며, 컨슈머 그룹 내에서 파티션 할당 및 오프셋 관리를 수행한다.
코디네이터의 주요 역할
- 컨슈머 그룹 관리 및 상태 유지
- 파티션 할당(Partition Assignment) 및 리밸런싱(Rebalancing) 수행
- 컨슈머 오프셋(Offset) 저장 및 조회
코디네이터는 컨슈머 그룹별로 다르게 할당될 수 있으며, 컨슈머 그룹 변경 또는 장애 발생 시 새로운 코디네이터가 자동으로 지정된다.
Kafka 클러스터 구성 예제
설정 예시
- 브로커(Broker) 개수: 3개 (Broker-1, Broker-2, Broker-3)
- 토픽(Topic) 개수: 2개 (Topic-X, Topic-Y)
- 각 토픽당 파티션 개수: 3개
- 예: Topic-X → Partition-0, Partition-1, Partition-2
- 예: Topic-Y → Partition-0, Partition-1, Partition-2
파티션 설정
Kafka는 파티션을 브로커에 분산 저장하며, 각 파티션의 리더(Leader)는 컨트롤러가 결정한다.
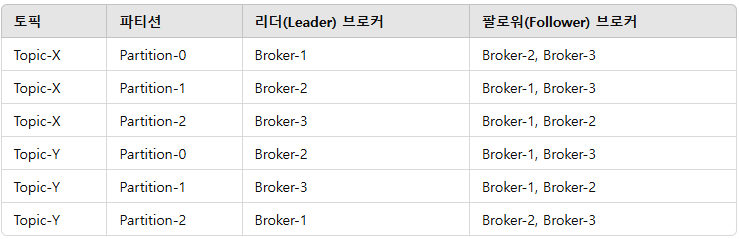
파티션 설정
- Kafka는 각 파티션의 리더를 다르게 지정하여 부하를 분산함.
- 각 파티션의 리더는 클라이언트의 읽기 및 쓰기 요청을 처리함.
- 팔로워는 리더의 데이터를 복제(Replication)하며, 리더 장애 시 자동으로 승격(Failover)됨.
- 브로커를 추가하면 새로운 브로커에도 파티션을 분산하여 할당할 수 있음
동작과정을 설명하자면
- 현재 Topic-X는 Partition-0, Partition-1, Partition-2 세 개의 파티션으로 구성되어있다.
- Kafka에서 읽기/쓰기는 리더(Leader) 파티션에서만 이루어진다.
- 따라서 현재 설정에서는
- Partition-0의 읽기/쓰기 → Broker-1(리더)에서 진행
- Partition-1의 읽기/쓰기 → Broker-2(리더)에서 진행
- Partition-2의 읽기/쓰기 → Broker-3(리더)에서 진행
장애 발생 시 동작
- Broker-1 장애 발생 → Partition-0의 리더가 없어짐
- 하지만, Partition-0의 팔로워가 Broker-2와 Broker-3에 존재
- Kafka의 컨트롤러(Controller)가 이를 감지하고, Broker-2를 Partition-0의 새로운 리더로 승격
- 이후부터 Partition-0에 대한 읽기/쓰기 작업은 Broker-2에서 진행
그래서 Kafka 클러스터란?
Kafka 클러스터는 여러 개의 브로커로 구성된 분산 시스템으로, 데이터의 고가용성(High Availability)과 확장성(Scalability)을 보장하는 Kafka의 핵심 구조이다. 클러스터 내에서 각 브로커는 특정 파티션을 관리하며, 컨트롤러는 클러스터 전체를 조정하고 리더 선출을 수행한다.
Kafka 클러스터의 주요 특징은 다음과 같다.
- 데이터 분산 저장: 메시지는 여러 브로커에 나뉘어 저장되어 부하를 분산한다.
- 장애 복구 기능: 리더 파티션이 장애 발생 시, 팔로워가 자동으로 승격되어 지속적인 데이터 처리가 가능하다.
- 확장성: 브로커를 추가함으로써 클러스터의 처리 성능을 쉽게 확장할 수 있다.
- 운영 최적화: Kafka 2.8부터는 KRaft를 통해 주키퍼 없이도 컨트롤러 선출 및 메타데이터 관리를 자체적으로 수행한다.
결국 Kafka 클러스터는 분산 환경에서 대용량 데이터를 안정적으로 처리하기 위한 핵심 아키텍처이며, 이를 통해 Kafka는 실시간 데이터 스트리밍에 최적화된 메시지 브로커 역할을 수행할 수 있다.
'Database , Middleware > Kafka' 카테고리의 다른 글
| [Kafka] Kafka 파티션, 컨슈머, 그룹 (파티션 리밸런싱, 컨슈머 리밸런싱) (0) | 2025.04.07 |
|---|

댓글